구조체 패딩에 관한 연구 및 성능 실험
목차
DB Reflection(해당 모든 변수의 런타임 정보를 담은 것)에 관한 개발 중, 모든 변수의 구조체로부터의offset을 기록하는 과정에서 문득 저장되는Data Class의 메모리 정렬 방식이 4byte, 8byte 혹은 1byte인 것이 퍼포먼스에 정말 중요하게 영향을 주는 것인가에 대해 궁금하여 연구를 진행했다.
구조체 패딩
왜 컴파일러는 구조체의 메모리를 정렬해 놓을까?
- 구조체 패딩 : 적은 수의 컴파일러는 구조체의 필드를 메모리에 위치시킬 때, 중간 빈 공간 없이 쭉 이어서 할당한다. 하지만 대부분의 컴파일러는 성능 향상을 위해 cpu가 접근하기 쉬운 위치에 필드를 배치하는 데 이를 구조체 패딩이라고 한다. 그리고 중간 빈 공간에 들어간 것을 패딩 비트라고 한다.
- 참고로 os 32bit 환경에서는 4byte packing 방식이 빠르고
- os 64bit 환경에서는 8byte packing 방식이 빠르다고 한다.
왜 빠를까?
- 패딩 비트가 없을 경우 어떤 일이 일어나는지 생각해보자.
- cpu는 메모리를 읽어올 때 한 번에 32bit os : 4byte 혹은 64bit os : 8byte를 읽어온다.
class Test
{
char _c1; // offsetof 0, size 1
int _i4; // offsetof 1, size 5
// 1byte packing을 하였다면
};
- ex)
char변수 1,int변수 1이 있는 구조체를 생각해보면, 32 bit os에서는int변수를 읽기 위해서 먼저 2~4 byte에 위치한 메모리를 읽어야 한다. 그러므로 cpu는 첫 4byte의 메모리를 읽는다. 그리고 5byte에 위치한 나머지int의 메모리를 읽기 위해 또 4byte의 메모리를 읽는다. - 만약 패딩 비트로
char뒤에 3byte가 채워져있었다면,int변수를 읽기 위해 한 번만 메모리를 읽어도 될 것을 2번 읽게 된 것이다. 이런 식으로 구조체 메모리를 정렬해놓으면 쓸데없이 메모리를 읽는 것을 막기 때문에 성능 저하가 발생하지 않는다. - Visual Studio 컴파일러
MSVC는 기본 packing 방식이 8byte로 지정되어 있다. (운영체제에 의존하는 방식이 아닌, 컴파일러에 의해 정해짐을 유의한다.)
어디에 주로 쓰일까?
- 네트워크를 통한 구조체 전송 시 구조체 패딩이 중요하다고 한다. (구조체를 그대로 직렬화 한 채 전송할 때)
- 서로 다른 컴퓨터 시스템에서 메모리를 읽는 방식이 다르기 때문에, packing 시 채워진 패딩 비트 때문에 각 컴퓨터에서 구조체를 다르게 읽을 수가 있기 때문이다. (그 시기에는 packing 정렬 방식을 1byte로 맞춰 놓는 방법으로 해결할 수 있다고 한다.)
- 사실 더 좋은 방법으로 DB Reflection을 통해, 변수들을 각각 대입한 뒤 직렬화한 후 전송하면 퍼포먼스도 향상시키고, 패딩 비트를 잘못 읽게 되는 경우도 해결할 수 있을 것 같다.
8 byte packing이라는 것은 무엇일까?
- offset을 확인해보니, 기본 packing 방식이 8byte여도 구조체의 크기가 8의 배수로 맞춰지지 않는다. 왜 그럴까?
- 8 byte packing이라는 것은 구조체의 메모리 정렬 방식을 8의 배수로 맞추겠다는 게 아니라, 8 보다 큰 변수가 있을 경우 정렬을 포기하겠다는 뜻이다.
- 즉 만약 packing 크기를 4로 바꾼다면,
double이나long long같은 타입들이 사용되었을 때는 더 이상 정렬을 보장하지 않게 된다. 그러므로 default packing 방식이 8인 것이다. - 쉽게 말하면 64bit os 혹은 32bit os에서 cpu가 한 번에 읽을 수 있게 패딩 비트를 통해 정렬해준다고 생각하면 될 것 같다.
구조체 패딩 퍼포먼스 실험
실험 1. 실무 검증 (Release 환경)
- DB의 모든 구조체를 4byte packing했을 시와, 8byte packing했을 시
- 실무에서 사용하는 389개의 리그레션 테스트 모듈을 모두 돌렸을 때의 시간을 비교
- 결과 시간 차이 없음 (측정하기 불가능할 정도로)
실험 2. 더미 데이터(테스트 베드) 구축
#pragma pack(push, 4)
class Test4
{
public:
int _int4 = 0;
double _double8 = 1000000000000000001.;
double _double800[100]; // = 전부 이걸로 초기화 1000000000000000001.;
private:
virtual void init() { }
}
#pragma pack(pop)
#pragma pack(push, 8)
class Test8
{
public:
int _int4 = 0;
double _double8 = 1000000000000000001.;
double _double800[100]; // = 전부 이걸로 초기화 1000000000000000001.;
private:
virtual void init() { }
}
#pragma pack(pop)
void TestPack4()
{
Test4 test;
auto _struct = sizeof(test); // 820
auto _i4 = sizeof(test._int4); // 4
auto _d8 = sizeof(test._double8); // 8
auto _d800 = sizeof(test._double800); // 800
auto _i4_offset = offsetof(Test4, Test4::_int4); // 8 (앞의 8 바이트는 가상 함수 테이블)
auto _d8_offset = offsetof(Test4, Test4::_double8); // 12
auto _d800_offset = offsetof(Test4, Test4::_double800); // 20
double aa[100];
// 4 pack
std::chrono::system_clock::time_point startTime = std::chrono::system_clock::now();
for (int i = 0; i < 1000000000; i++) // or 10000000000
{
aa[i%100] = test._double800[i%100];
test._double800[i%100] = aa[i%100];
}
std::chrono::system_clock::time_point endTime = std::chrono::system_clock::now();
std::chrono::duration<double> defaultSec = endTime - startTime;
std::chrono::nanoseconds nano = endTime - startTime;
std::chrono::microseconds micro = std::chrono::duration_cast<std::chrono::microseconds>(nano);
std::chrono::milliseconds mill = std::chrono::duration_cast<std::chrono::milliseconds>(nano);
}
void Test1Pack8()
{
Test8 test;
auto _struct = sizeof(test); // 824
auto _i4 = sizeof(test._int4); // 4
auto _d8 = sizeof(test._double8); // 8
auto _d800 = sizeof(test._double800); // 800
auto _i4_offset = offsetof(Test8, Test8::_int4); // 8 (앞의 8 바이트는 가상 함수 테이블)
auto _d8_offset = offsetof(Test8, Test8::_double8); // 16 (_i4_offset 뒤의 4바이트가 패딩 비트로 들어감)
auto _d800_offset = offsetof(Test8, Test8::_double800); // 24
double aa[100];
// 8 pack
std::chrono::system_clock::time_point startTime = std::chrono::system_clock::now();
for (int i = 0; i < 1000000000; i++) // or 10000000000
{
aa[i%100] = test._double800[i%100];
test._double800[i%100] = aa[i%100];
}
std::chrono::system_clock::time_point endTime = std::chrono::system_clock::now();
std::chrono::duration<double> defaultSec = endTime - startTime;
std::chrono::nanoseconds nano = endTime - startTime;
std::chrono::microseconds micro = std::chrono::duration_cast<std::chrono::microseconds>(nano);
std::chrono::milliseconds mill = std::chrono::duration_cast<std::chrono::milliseconds>(nano);
// mill millsec로 테스트 진행
}
- 64bit os에서 8바이트 패킹을 했을 때와 그렇지 않을 때 얼마나 더 퍼포먼스 적으로 이득일까를 실험했다.
- 64bit os에서 4byte packing 한 구조체 중 막대하게 손해 볼 수밖에 없는 구조체를 가상으로 생성한다.(
int다음 필드부터 계속 한 칸씩 밀리기 때문에 cpu가 계속 2번씩 읽어야 하는 경우를 구현) - 여러 반복을 통한 시간 검증한다. (8byte packing과, 4byte packing에 대한 시간 비교)
- 1,000,000,000의 반복문과, 10,000,000,000의 반복문에서 반복을 진행하고, 해당 내용은 구조체 내에서 정렬되지 않은 특정 변수의 읽고 쓰는 시간(
milliseconds)을 측정한다. (1,000,000,000의 반복문 이하의 반복은 시간이 거의 차이가 없기 때문에 실험이 불필요)
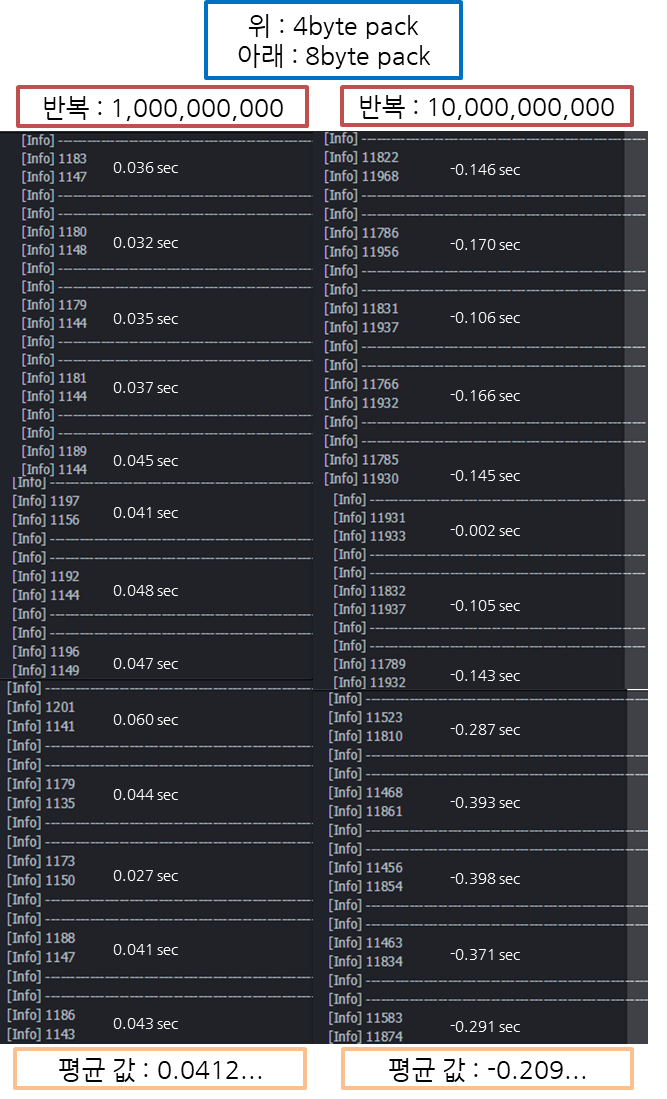
- 위 그림의 실험 결과대로, 1,000,000,000의 반복문에서는 올바르게 8바이트 정렬했을 때 약 0.04초 더 빠르다.
- 1,000,000,000의 반복문에서는 오히려 약 0.2초 정도 더 느려진다.
- 여러 번의 테스트 결과 역시나 약 0.04초에서 0.2 시간이 차이 나는 것이 의미가 있는지 모르겠다…
- 비율로 봐도 일정한 비율이 나오지 않는다.
- 아마 os 단에서 최적화하거나, cpu가 최적화하거나, 컴파일러가 최적화하는 알고리즘이 있는 것 같다.
결론
- 오버헤드가 있다고 알고 있었고, c++ 개발자로서 변수의 순서를 생각하며 메모리 정렬을 효과적으로 하는 것이 좋다고 생각하고 있었다.
- 하지만 직접 실험해본 결과 퍼포먼스 적으로는 의미가 있는 행위인지 잘 모르겠다.
- 어쨌든 테스트 베드 환경을 만들던, 실무 모델로 테스트하던 큰 차이가 없었고(비율적으로도 시간적으로도), 이런 환경에서 os, cpu, 컴파일러 누가 최적화해줬든 간에, 일반 개발자들은 구조체 정렬을 생각하며 개발해야 한다는 것은 잘 모르겠다…
- 네트워크 개발 시 서로 다른 os 별 bit 수가 다를 때 1byte로 packing 해야 하는 경우 말고는 크게 의미 없는 것 같다.
- 아니면 혹시 실험을 잘못했을까..?