MySQL online-ddl 기능을 사용하며 분석하던 중, 관련하여 MySQL 5.6 신기능에 대해 함께 정리해보았습니다.
목차
1. ICP(Index Condition Pushdown)
Select 쿼리 최적화에 해당한다.
선행 개념
MySQL은 DB 엔진과 스토리지 엔진이 분리된 구조로 되어 있다.
MySQL DB 엔진은 쿼리 파싱과 실행 계획 생성 및 수행을 담당하고, 각 스토리지 엔진이 데이터와 인덱스 및 물리적인 I/O 작업을 관리한다.
배경
이런 MySQL의 내부 구조로 인하여 쿼리 처리에 비효율이 발생하는 부분이 있는데, 대표적인 예가 Index에서 필터링을 수행하지 못하는 것이다.
예를 들어 아래와 같은 조건의 인덱스와 쿼리가 있다고 가정했을 때,
상식적으로는 인덱스에서 2개의 조건을 만족하는 데이터만 조회해서, 클라이언트에 결과를 돌려주면 된다.
# 인덱스 : zipcode + lastname
SELECT * FROM people WHERE zipcode='95054' AND lastname LIKE '%ho%'
하지만 MySQL에서는 전혀 다르게 동작을 한다.
위 쿼리는 ref 타입의 실행 계획으로 처리되며, MySQL 엔진(옵티마이저)은 스토리지 엔진에게 zipcode=95043이라는 조건밖에 전달하지 못한다.
스토리지 엔진은 lastname LIKE ‘%ho%’ 라는 조건을 알 수 없기에, zipcode가 95054인 데이터 모두를 MySQL 엔진으로 전달할 수 밖에 없다.
그리고 쿼리의 조건에 맞지 않는 데이터는 MySQL 엔진에서 필터링 처리되어 버려지게 된다.
즉, 읽지 않아도 될 데이터를 읽어서 전달한 셈이다.
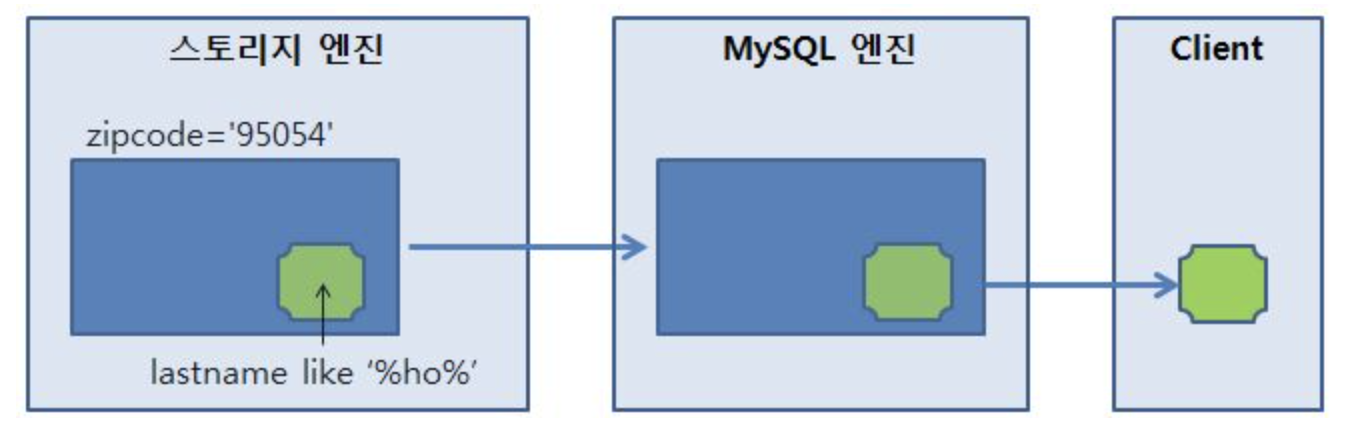
기존 MySQL의 데이터 처리 단계
해결
하지만 최근 개발 버전이 발표된 MySQL 5.6 버전에서는 Index Condition Pushdown(ICP)라는 기능이 추가된다.
이 기능은 WHERE 필터 조건(Condition)을 스토리지 엔진으로 밀어넣을(Pushdown) 수 있도록 해주는 기능이다.
MySQL 5.6 버전의 옵티마이저 개선 내용 중에 가장 기대되는 부분이기도 하다.
ICP 기능의 적용으로 DB 내부에서는 불필요한 I/O 및 데이터 전송 과정이 줄어들게 되고, 클라이언트 입장에서는 보다 빠른 응답 성능을 기대할 수 있다.
ICP 최적화는 InnoDB, MyISAM 스토리지엔진에 구현되었고, range, eq_ref, ref, ref_or_null 타입의 쿼리에 적용된다고 한다.
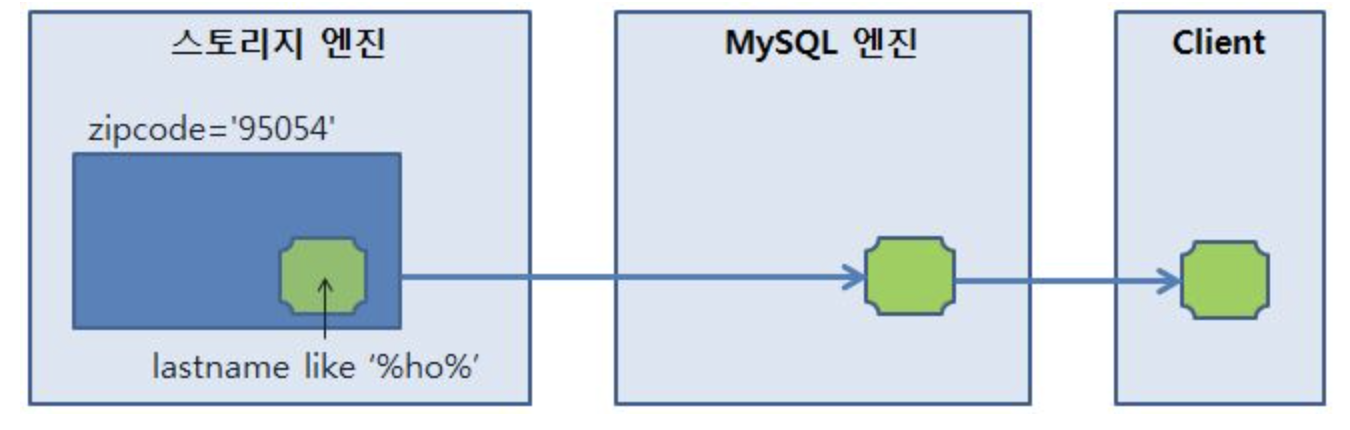
MySQL 5.6 버전의 데이터 처리 단계 - ICP 적용
사용 법
인덱스 조건 푸시 다운은 기본적으로 활성화된다.
플래그 optimizer_switch, index_condition_pushdown를 설정하여 시스템 변수로 제어 할 수 있다.
SET optimizer_switch = 'index_condition_pushdown=off';
SET optimizer_switch = 'index_condition_pushdown=on';
2. MRR(Multi Range Read)
Select 쿼리 최적화에 해당한다.
배경
보조 인덱스에서 범위 스캔을 사용하여 행을 읽으면 테이블이 크고 스토리지 엔진의 캐시에 저장되지 않은 경우 기본 테이블에 대한 임의 디스크 액세스가 많이 발생할 수 있다.
해결
Disk-Sweep Multi-Range Read (MRR) 최적화를 통해 MySQL은 먼저 인덱스 만 스캔하고 관련 행에 대한 키를 수집하여 범위 스캔에 대한 임의 디스크 액세스 수를 줄이려고한다. 그런 다음 키가 정렬되고 마지막으로 기본 키의 순서를 사용하여 기본 테이블에서 행이 검색된다. Disk-sweep MRR의 동기는 무작위 디스크 액세스 수를 줄이고 대신 기본 테이블 데이터를보다 순차적으로 스캔하는 것이다.
MySQL 5.6 버전에서는 옵티마이저에 많은 개선이 적용되었는데, Index Condition Pushdown과 함께 Multi Range Read 기능의 도입을 대표적인 예로 들수있다.
Multi Range Read(MRR)는 Random I/O를 Sequential I/O로 처리할 수 있도록 도와주는 기능으로, Non-Clustered Index를 통해 Range Scan을 하는 경우, 바로 데이터를 조회하지 않고 어느 정도 rowid(primary key) 값들을 Random 버퍼(read_rnd_buffer_size)에 채운 다음, 버퍼 내용을 정렬하여 최대한 rowid(primary key) 순서대로 데이터를 접근할 수 있도록 해주는 것이다.
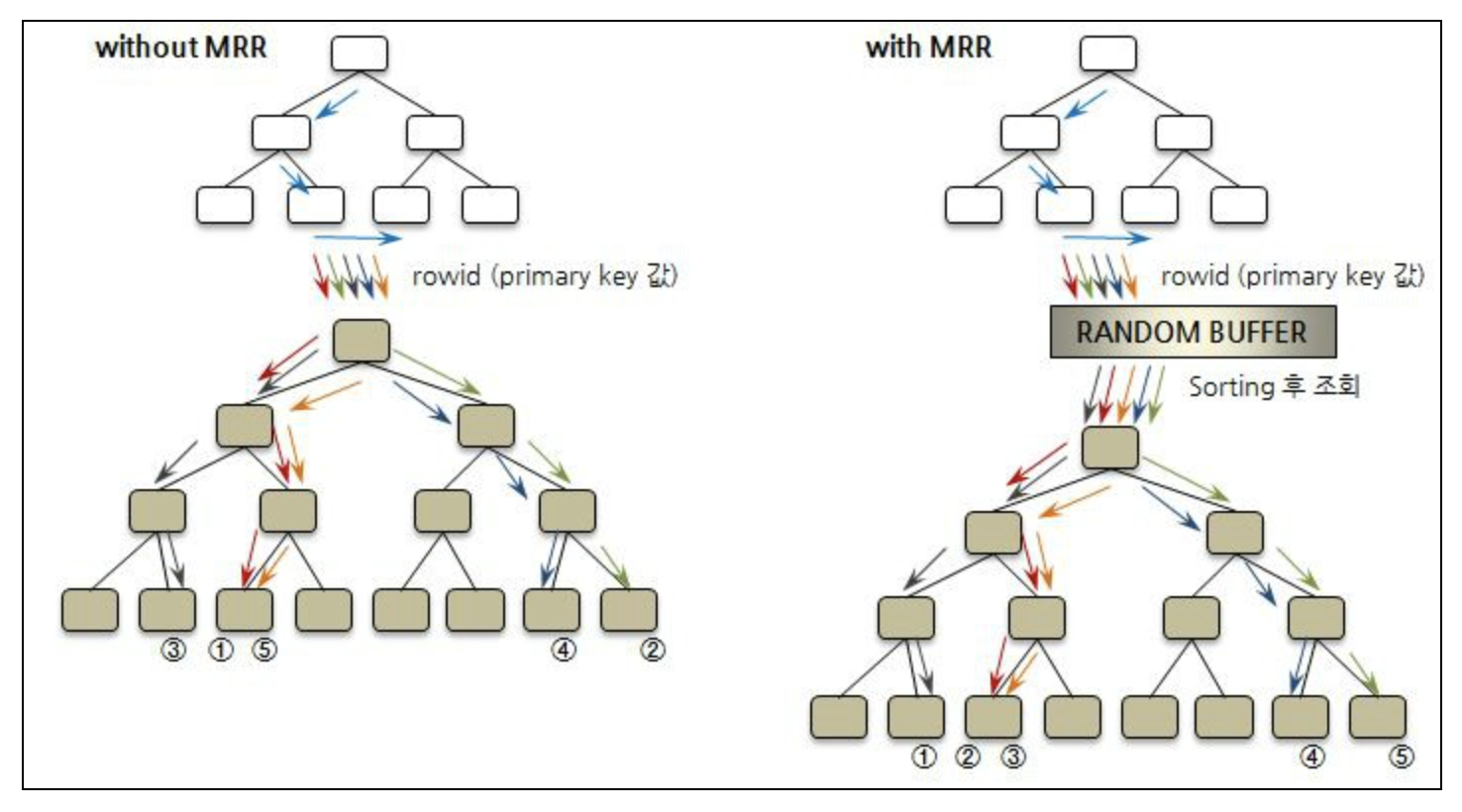
광범위한 Range Scan 상황을 가정해서 테스트 해본 결과, Multi Range Read(MRR) 기능이 Non-Clustered Index의 Scan 성능 향상에 도움이 되며, Random 버퍼의 사이즈를 늘려주면 그 효과 또한 높아지는 것을 확인할 수 있었다. 그렇다고 세션마다 할당되는 Random 버퍼를 무작정 키우는 경우, 다른 문제를 일으킬 수 있으므로 유의가 필요하다. (16MB도 충분히 큰 사이즈이다.)
사용 법
기본적으로는 on 상태이다.
# 디비 엔진 설정: switch
set optimizer_switch = 'mrr=on'; // default
set optimizer_switch = 'mrr=off';
# 스토리지 엔진 설정: 랜덤 버퍼 사이즈 설정
set read_rnd_buffer_size = 16777216; # 16MB
3. BKA(Batched Key Access)
배경
Batched Key Access(BKA) 조인 알고리즘이 Multi Range Read(MRR) 기능을 사용하고 있다!
일반적인 Nested Loop 조인(NLJ) 과정을 살펴보면 먼저 읽혀지는 선행 테이블(Driving Table)에서 조회되는 값으로 조인되는 테이블(Joined Table)을 접근하게 되는데, 조인되는 테이블(Joined Table) 입장에서는 데이터 저장 순서대로 조회를 하는 것이 아니기 때문에 다량의 Random I/O가 발생하게 된다.
해결
Batched Key Access(BKA)는 Nested Loop 조인(NLJ)의 Random I/O 발생을 줄이기 위해 Multi Range Read(MRR) 기능을 사용한다.
- 먼저 읽혀지는 선행 테이블(Driving Table)에서 조회되는 값들을 먼저 조인 버퍼(join_buffer_size)에 채운다.
- 조인 버퍼에 채워진 내용을 기준으로, 조인되는 테이블(Joined Table)의 rowid(primary key) 값을 구한다. (인덱스 Lookup)
- 빌드된 rowid(primary key) 값으로 조인되는 테이블(Joined Table)을 대상으로 Multi Range Read(MRR) 연산을 수행한다.
- 결과 값을 조인 버퍼(join_buffer_size)에 채워진 선행 테이블(Driving Table) 값과 연결한다.
사용 법
기본값은 off 이다.
SET optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';
# mrr은 default로 on이며
# 현재 MRR에 대한 비용 추정은 너무 비관적입니다. 그러므로 mrr_cost_based off로
# 마지막으로 BKA 사용할 수 있도록 활성화합니다.
4. Online DDL (중요!)
DDL 쿼리 최적화에 해당한다.
배경
전통적으로 MySQL에서 테이블 스키마 변경(ALTER) 작업을 수행하면, 내부적으로는 변경된 스키마로 임시 테이블을 만들어서 데이터를 부어넣는 작업이 수행한다.
이는 작업 대상 테이블의 전체 데이터/인덱스를 리빌드하는 고비용의 작업이며, 작업이 진행되는 동안에는 해당 테이블에 대한 SELECT 쿼리 이외의 DML 쿼리들이 대기 상태에 빠지게 되기 때문에 서비스 가용성을 떨어뜨리는 결과를 가져온다.
혹은 사용량이 적은 새벽 시간에 스키마 변경 작업을 수행하게 되어 DBA를 체력을 떨어뜨리기도 한다 :(
해결
MySQL 5.6 버전에서는 Online DDL 이라는 기특한 기능이 추가되어서 위와 같은 문제들이 대부분 해소되었다.
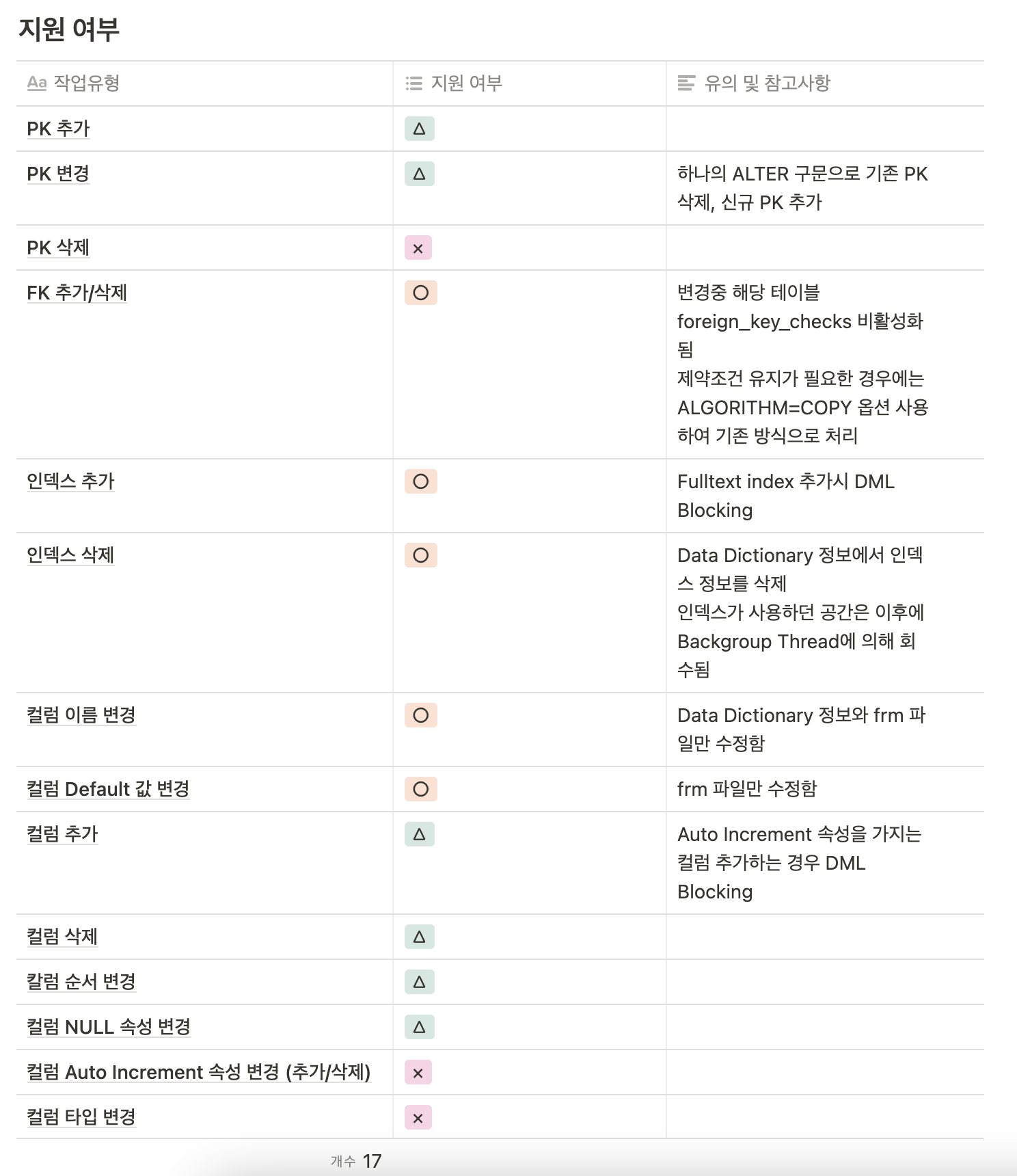
작업 종류별로 처리 방식과 유의해야 될 내용에 차이가 존재하고, 메뉴얼의 설명이 좀 복잡하게 되어 있어 작업 종류별로 3가지 패턴으로 Online DDL 가능 여부를 정리해 보았다.
작업유형
표로 간단하게 정리해보았다. 더욱 더 자세한 내용은 Reference에 있는 MySQL 공식 홈페이지에서 확인할 수 있다.
사용 법
이름에서 볼 수 있듯이 ddl에 서 사용할 수 있다.
ALGORITHM 구와 아래와 같이 지정할 수 있다.
INPLACE: 인프레이스로 수행하는 방식이다.COPY: 복사를 통해 수행하는 방식이다.
이 구문을 지정하지 않는 경우 즉 생략한 경우에는 INPLACE -> COPY 순으로 DDL 구문에 맞게 자동으로 선택된다.
LOCK 구는 아래와 같이 지정할 수 있다.
NONE: 잠금을 걸지 않는 방식(read, write허가)으로 동시DML을 허가한다는 뜻이다.SHARE: 공유잠금을 거는 방식으로(read허가)으로 동시DML을 허가하지 않는다는 뜻이다.EXCLUSIVE: 배타잠금을 거는 방식으로 동시DML을 허가하지 않는다는 뜻이다.
이 구문을 지정하지 않는 경우 즉 생략한 경우에는 NONE -> SHARE -> EXCLUSIVE 순으로 DDL 구문에 맞게 자동으로 선택된다.
일반적인 예시는 아래와 같다.
ALTER TABLE `TableName` ADD COLUMN `columnName` varchar(200) DEFAULT NULL,
ALGORITHM=INPLACE, LOCK=NONE; // 이 부분이 핵심!
Reference
- MySQL :: MySQL 5.6 Reference Manual :: 8.2.1.5 Index Condition Pushdown Optimization
- MySQL :: MySQL 5.6 Reference Manual :: 8.2.1.10 Multi-Range Read Optimization
- MySQL :: MySQL 5.6 Reference Manual :: 8.2.1.11 Block Nested-Loop and Batched Key Access Joins
- MySQL 5.6 신기능 - Online DDL
- https://dev.mysql.com/doc/refman/5.6/en/innodb-online-ddl.html