목차
Intro
분명 제대로 보이는 한글 이름의 파일을 내려받았는데 읽을 수 없는 이상한 이름으로 저장된 파일을 받아본 경험이 있을 것입니다. 보통 ‘인코딩이 깨졌다.’라고 말하는 이런 상황은 왜 발생하는 것일까요? 그 이유는 컴퓨터에서 한글을 표현하는 다양한 방식이 있는데 해당 방식이 서로 맞지 않기 때문입니다.
컴퓨터 발명 초기에는 문자를 표현해야 하는 요구가 많이 없었습니다. 그러나 계속해서 이러한 요구가 생겨났고, 컴퓨터끼리 데이터를 교환해야 하는 일이 생기기도 했습니다. 때문에 컴퓨터끼리 문자 데이터를 교환해야 하는 표준이 필요하게 되었고, 결국에는 ASCII와 같은 표준 문자 인코딩이 만들어지게 되었습니다.
문자를 표현하기 위해서는 가장 먼저 ‘문자 집합‘을 정의해야 합니다. 문자 집합은 표현해야 할 문자를 정하고 순서를 지정한 것입니다. 영어라면 A부터 Z까지입니다. 이러한 숫자와 문자뿐만 아니라 통신을 제어하기 위한 제어 문자도 포함되어야 합니다. 그리고 이러한 문자 집합을 코드 형태로 표현한 것을 코드화된 문자 집합이라고 합니다. 그리고 문자 집합을 컴퓨터에 저장하기 위해서 어떠한 형태로 표현한 것을 인코딩 방식이라고 합니다.
이러한 역사를 토대로 문자를 컴퓨터로 표현하던 중, 영어뿐만 아니라 한글, 한자, 일본에서 사용하는 문자 집합을 처리할 필요성을 느끼게 되었고, 아쉽게도 그 개수가 너무 많아 확장된 ASCII 코드로도 이를 모두 처리할 수 없게 되었습니다. 따라서 이러한 문자를 처리하기 위한 별도의 방안이 필요하게 되었습니다. 결국 세상의 모든 문자 집합의 표준을 만들기 위해 Unicode라는 것이 나오게 되었습니다.
Intro 정리
- 컴퓨터에서 문자를 표현하는 방식에는 다양한 방식이 있다. (여러 인코딩 방식이 있다.)
- 문자 집합 : 표현해야 할 문자를 정하고 순서를 지정한 것
- 코드화된 문자 집합 : 문자 집합을 코드 형태로 표현한 것
- 인코딩 방식 : 문자 집합을 컴퓨터에 저장하기 위해서 어떠한 형태로 표현한 것
- ASCII : 초기에 널리 쓰이던 표준 문자 인코딩 (영어와 확장 ASCII에서는 유럽어도 표현이 가능, 확장 ASCII는 ANSI라고도 불림)
- Unicode : 모든 문자를 표현할 수 있도록 만들어진 표준 문자 집합
유니코드
유니코드란??
유니코드(Unicode)는 전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 표준입니다.
유니코드의 포함 내용
유니코드는 코드화된 유니코드 문자(Unicode Character Set : ISO 10646) 뿐만 아니라 문자 정보 데이터베이스, 문자를 다루는 알고리즘, 문화권을 포함하는 개념입니다. 예를 들어 다음과 같은 것이 있습니다.
- 문자의 표기 방향 (문자의 Data 순서와 시각적 표기 순서의 차이 : 아랍어는 왼쪽에서 오른쪽으로 작성한다)
- 문자의 조립, 분해 방식 (예 : 한글 - ㅎㅏㄴㄱㅡㄹ)
- 렌더링 방식
- 두 문자의 우선순위 비교 방법
- 숫자의 구분자 표기 방법
- …
유니코드의 여러 인코딩 방식 (UCS, UTF)
유니코드의 인코딩 방식을 이해하려면 먼저 Code Point에 대해 알아야 합니다. Code Point란 유니코드 값을 나타내기 위해 사용하는 것으로서, 보통 U+를 붙여 표시합니다. 유니코드의 인코딩 방식은 이러한 Code Point를 고정 크기로 인코딩한 UCS-2와 UCS-4, 그리고 가변 크기로 인코딩한 UTF-8, UTF-16, UTF-32로 나눌 수 있습니다.
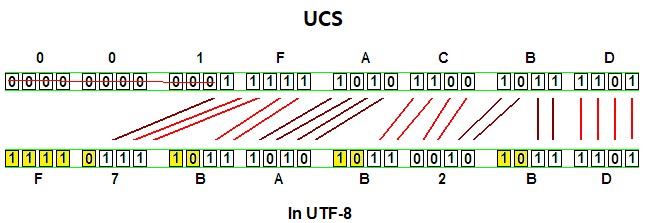
UCS
UCS는 유니코드를 위한 고정 길이 문자 인코딩 방식입니다.
UCS-2 (1 : 2)
- 1개의 문자를 2 byte인 16-bit에 저장한다고 하여
UCS-2라고 명명하였습니다. - 일반적으로 사용하는 문자들을 모두 표현할 수 있습니다.
UCS-4 (1 : 4)
- 1개의 문자를 4 byte인 32-bit에 저장한다고 하여
UCS-4라고 명명하였습니다. UCS-4는 4개의 byte를 사용하여 현재 세상의 모든 문자를 표기할 수 있는 코드(Code Point)입니다.
Unicode Transformation Format (UTF)
- UTF는 유니코드를 위한 가변 길이 문자 인코딩 방식입니다.
- 각각의 UTF-x로 인코딩된 코드를 디코딩 하면 이에 해당하는 Unicode Code Point를 획득할 수 있도록 설계되어 있습니다.
UTF-8
- ASCII 기반 응용프로그램이나 파일 시스템에서는 2바이트의 유니코드 문자를 1바이트씩 따로 읽기 때문에 잘못된 해석을 하게 됩니다. 그런 문제점을 해결하고자 UTF-8은 고정 길이의 유니코드 문자를 가변 길이 ASCII-Safe 바이트 문자열로 변환하여 해석합니다.
- 이런 방법으로 UTF-8은 ASCII를 기반으로 확장한 인코딩 방법입니다.
- ASCII와 호완이 가능하면서 유니코드를 표현할 수 있기 때문에 가장 많이 사용됩니다.
UTF-16, UTF-32
- 마찬가지로 각 인코딩 환경을 기반으로 확장한 인코딩 방법입니다.
- UTF-16은 UCS-2를 기반으로 확장한 인코딩 방법
- UTF-32는 UCS-4를 기반으로 확장한 인코딩 방법
- UTF-16의 경우에는 CPU의 엔디안(Endian)처리 방식에 따라 조금 다르게 인식될 수 있습니다. (BigEndian은 UTF-16BE, LittleEndian은 UTF-16LE)
- UTF-16의 엔디안(Endian)을 구분하기 위해 파일의 시작 지점에 BOM(Byte Order Mark : 0xFEFF)를 표준에서 허용하고 있습니다. (4 byte를 읽었을 때 0xFE 0xFF, 0xFF 0xFE 인지에 따라 Endian 처리를 판단함)
- UTF-16에서 BOM이 없는 경우 Big Endian을 기본값으로 가정합니다. (Intel CPU를 사용하는 Windows는 Little Endian이 기본값이라 표준과 조금 어긋나있습니다.)
정리
- 1개의 문자는 1개의 코드(Code Point)에 대응합니다.
UCS-2에서는16-bit가1개의 문자로 대응UCS-4에서는32-bit가1개의 문자로 대응
- 일반적으로 Unicode Code Point를 표준으로 사용합니다.
- 유니코드 문자의 좌표는 U+xxxx 형태로 표현 (예 :
U+1F61B-> 😛)
- 유니코드 문자의 좌표는 U+xxxx 형태로 표현 (예 :
Unicode vs. UCS vs. UTF
Unicode
- 문자를 표현하기 위한 표준안입니다.
- 표기 순서, 정렬 방식, 문화권 차이 등의 알고리즘을 포함하는 포괄적인 개념입니다.
UCS
- 어떠한 문자를 1개의 코드(Code Point)에 대응한 것에 대한 표준입니다.
- UCS-2는 문자를 16-bit에 대응한 것으로 일반적/일상적으로 사용하는 문자들(BMP 영역)이 여기에 속해있습니다.
- UCS-4는 문자를 32-bit에 대응한 것으로 UCS-2에서 표현할 수 없었던 고대 상형문자, 이모티콘 등을 포함하는 전체 유니코드 영역을 표현합니다.
UTF
- 위의 UCS를 가변 크기로 인코딩하는 방식 또는 알고리즘입니다.
- UTF-8은 UCS를 ASCII 기반, 8-bit 단위로 인코딩한 것입니다.
- UTF-16은 UCS를 UCS-2 기반, 16-bit 단위로 인코딩한 것입니다.
- UTF-32는 UCS를 UCS-4 기반, 32-bit 단위로 인코딩한 것입니다.
Unicodes in Software
- W3C : 모든 웹 표준 파일은
UTF-8을 기본으로 사용합니다. (JSON, XML, HTML, CSS 등) - Windows :
UTF-16을 기본으로 사용합니다. - Javascript : 많은 엔진 코드가
UCS-2또는UTF-16을 기본으로 사용합니다. - Python :
UCS-2를 기본으로 사용하지만 빌드 옵션에서UTF-32로 바꿔서 사용이 가능합니다. - International Components for Unicode (ICU) : 내부적으로
UTF-16을 기본으로 사용하고 있습니다.
Unicode in C++
wchar_t는 원래 8-bit보다 큰 문자를 표기하기 위해 정의한 형식입니다. (표준안에서 몇 bit를 사용해야 하는지 정의하지 않음)- Windows : 16-bit를 사용하고 있으며,
UTF-16데이터를 넣어서 사용합니다. - 나머지(일반적으로) : 32-bit를 사용하고 있으며,
UTF-32데이터를 넣어서 사용합니다. - C++11에서 명시적인 자료형이 추가되었습니다. (
char16_t,char32_t)
const char str1[] = u8"여기는 UTF-8"; // std::string과 대응, 계당 2byte
const char16_t str2[] = u"여기는 UTF-16"; // std::u16string과 대응, 계당 2byte
const wchar_t str3[] = L"여기는 UTF-16"; // std::wstring과 대응, 계당 2byte
const char32_t str4[] = U"여기는 UTF-32"; // std::u32string과 대응, 계당 4byte
Unicode in Java
- Java(JVM) : Java의
String은UTF-16를 기본으로 사용합니다. - Java에서 문자열 전송/수신을 위해서 직렬화가 필요할 때 :
UTF-8을 기본으로 사용합니다.
Unicode in Windows
Windows Code Page : 1980년대에서 1990년대까지 사용했던 Windows의 고유 문자 코드(Code Point) 처리 방식
- 크게 ANSI Code Page와 OEM Code Page를 가지고 있습니다.
- 51949 : EUC-KR Code Page로 2000년대 초반 우리나라에서 많이 사용하던 형식입니다.
- 65001 : UTF-8 Code Page로 표준화된 통신을 위해서는 이 코드를 사용해서 변환해야 합니다.
- 949 : ANSI/OEM Korean Code Page로 EUC-KR에서 표기할 수 없는 문자를 개선한 확장된 버전입니다. (한글 OS에서 ASCII 형식으로 불러올 때의 기본 인코딩 방식)
- 메모장에서 볼 수 있는 인코딩 ANSI는 ASCII의 확장만을 의미하는 게 아니라, EUC-KR에서 개선된 위의 방식을 의미합니다. 그렇기 때문에 한글을 저장할 수 있는 것입니다.
Windows Kernel : 내부적으로 16-bit로 된 wchar_t인 UTF-16을 기본으로 사용합니다.
- TCHAR 계열을 사용하여 개발할 경우 유니코드로 빌드 할 경우 wchar_t로 변환하여 빌드가 됩니다.
- 기존 코드 호환을 위해 ~~~A와 ~~~W 두 가지 함수를 제공하고 있으며 ~~~A함수를 호출할 경우 내부적으로 wchar_t로 변환한 후 ~~~W를 호출하게 되어있습니다.
Windows Programming Tips
- Windows에서는
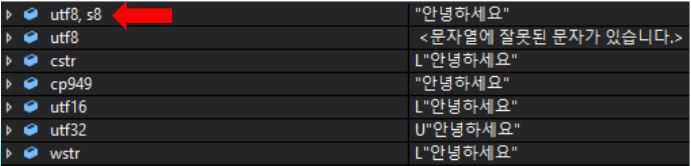
UTF-16 + BOM으로 파일을 저장해야 올바르게 유니코드 파일이라고 인식합니다. (예 : 메모장 프로그램 등) - 팁 : Visual Studio에서 ‘s8’옵션을 사용하면 UTF-8로 인코딩된 텍스트가 디버그 창에서 올바르게 표기됩니다.
한글 코드의 표현 방식
유니코드 상에서 한글은 각각의 자모와 그 조합으로 구성되어 있습니다. 각 인코딩 방식을 파악하고 해당 환경에서 지원되는 방법으로 인코딩하여 문자를 전송한다면 해당 환경과의 통신은 원활하게 될 것입니다. 그런데 다양한 환경으로 이루어진 웹상에서는 어떻게 한글과 여러 문자들을 표현해야 할까요??
웹과 한글
한글 처리, 특히 웹에서의 한글 처리는 무척 까다롭습니다. 그 이유는 사용자의 환경이 매우 다르다는 데 있습니다. 웹 프로그래밍을 하려면, 운영체제의 기본 인코딩, Java 소스 코드의 인코딩, JSP 파일의 인코딩, HTTP 요청의 인코딩, HTTP 응답의 인코딩, 데이터베이스의 인코딩, 파일의 인코딩 - 이렇게 많은 인코딩과 마주하게 됩니다.
일단 웹에서 한글이 깨지는 이유는? 이제는 알 수 있듯이 브라우저의 인코딩 값과 서버의 인코딩 값이 달라서 문자를 온전하게 읽을 수 없기 때문입니다. 웹에서 여러 인코딩을 지원하고 싶다면 인코딩된 URL 문자열과, 사용한 인코딩 정보를 파라미터로 같이 전달해야 합니다. 이런 방식을 이용하면 여러 인코딩 방식을 지원하는 환경을 구성할 수 있습니다.
물론 위에서 말했다시피 웹상에서의 인코딩 방식의 표준은 UTF-8입니다.
결론
컴퓨터에서 어떠한 문자를 저장했을 때, 해당 응용프로그램이나 파일 시스템, 환경에서 특정 문자를 확실하게 전달하고 싶다면, 지금까지 정리한 인코딩 방식에 대해 잘 알고 있다면 많은 도움이 될 것입니다.
그에 대한 제 경험으로 한 오픈 소스에서 특정 파일을 읽을 때 영어 밖에 지원하지 않아 확장하던 중, 다국어 지원이 가능하고 해당 운영체제나 환경을 고려해서 프로그램을 만들어야 할 일이 생겼습니다. 아무리 찾아봐도 명쾌하게 정리가 되지 않아 글을 쓰기 시작했는데, 혹시나 제가 틀린 부분이 있다면 지적해주시면 감사하겠습니다.